This talk introduces an approach to embedded development: running the GNU Debugger (GDB) directly in the browser using WebAssembly, eliminating the need for traditional installations.
Attendees will discover how this solution can be integrated by leveraging the Eclipse CDT Cloud Project targeting popular web based IDEs such as Visual Studio Code (VSCode) and Eclipse Theia. By using WebAssembly, we can run GDB directly in the browser, providing a seamless debugging environment across different systems.
In addition, the talk will cover the exciting capabilities of modern browsers to connect to hardware using WebUSB. This allows developers to interface with embedded devices directly from the browser, further simplifying the development and debugging process.
Join us to explore the future of zero-install embedded C/C++ development and see firsthand how these technologies can revolutionize your development experience.
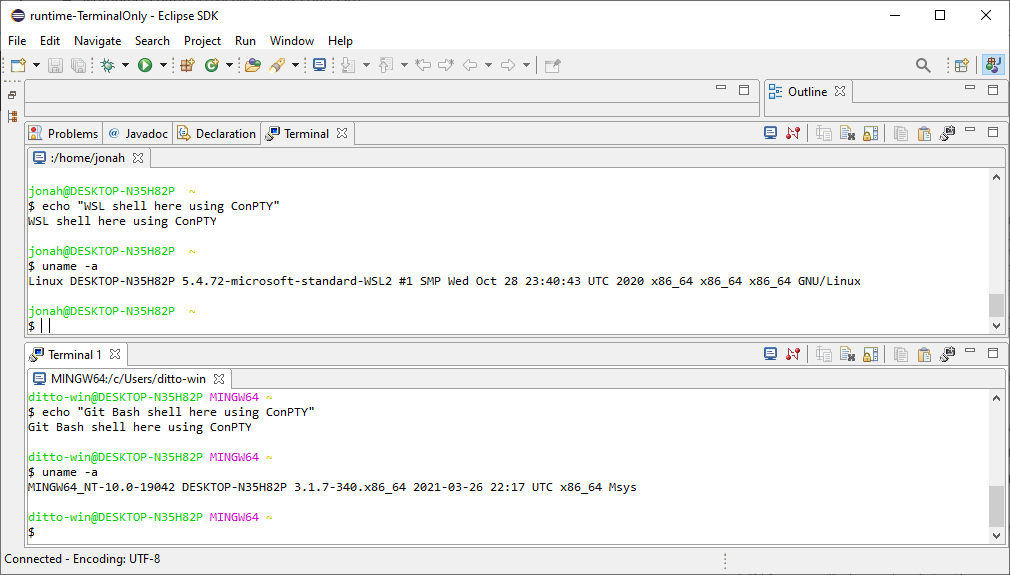
For many years the Eclipse IDE has provided an integrated terminal (called Eclipse TM Terminal) and now maintained by the Eclipse CDT team. On Windows the terminal uses the amazing WinPTY library to provide a PTY as Windows did not come with one. For the last number of years, Windows 10 has a native version called Windows Pseudo Console (ConPTY) which programs such as VSCode and Eclipse Theia have converted to using, in part because of the fundamental bugs that can’t be fixed in WinPTY. The WinPTY version in Eclipse is also quite out of date, and hard to develop as it is interfaced to by JNI.
For Eclipse 2021-06 the Eclipse CDT will be releasing a preview version of the terminal that will use ConPTY. For interfacing to ConPTY we are using JNA which is much easier to develop because all the interfacing is in the Java code.
One of the open questions I had was whether there would be a performance issue because of the change to ConPTY. In particular, while JNA is slower for some things the ease of use of JNA normally far outweighs the performance hit. But I wanted to make sure our use case wasn’t a problem and that there wasn’t anything else getting in the way of the terminal’s performance.
Shell to Eclipse Terminal Performance
I have analyzed the performance of a process running in the shell writing to stdout as fast as possible to compare various different terminal options on my Windows machine. The Java program creates a byte[] of configurable size and writes that all to System.out.write() in one go, with some simple wall clock timing around it. See the SpeedTest attachment for the source.
I used 5 terminal programs to test the performance:
Windows Command – the classic terminal when you run cmd.exe for example
And in each of them I ran the same Java program in 3 different shells:
cmd.exe
WSL2 running Ubuntu bash
git bash
Short summary is that WinPTY and Windows Command are much faster than the rest. ConPTY is quite a bit slower, whether used in Eclipse or Windows Terminal. VSCode is dramatically slower than the rest.
cmd.exe
WSL2
git bash
Windows Command
8.3
3.5
4.2
Eclipse with WinPTY
12.5
1.6
7.7
Eclipse with ConPTY
1.8
1.7
2.0
Windows Terminal
2.2
2.1
2.4
VSCode
0.8
0.8
0.8
Full table of results based on a 10MiB write, reported in MiB/second, rounded to nearest 0.1 MiB/s:
As a comparison, on the same machine dual-booted into Xubuntu 18.04 I ran the following 5 terminals:
Eclipse – 23.1 MiB/s
VSCode – 3.0 MiB/s
xterm – 6.3 MiB/s
xfce4-terminal – 10.7 MiB/s
gnome-terminal – 10.2 MiB/s
The above shows that the raw speed of Eclipse Terminal is very good, it simply requires the best possible PTY layer to achieve the best speeds.
Eclipse Terminal to Shell Performance
I was going to run an Eclipse -> Shell test to make sure writes to the terminal hadn’t regressed. However the terminal has an artificial throttle in this path that limits performance to around 0.01 MiB/s, plenty fast to type, but much slower than a performant system could be. The code could probably be revisited because presumably the new ConPTY does not suffer from these buffering issues, and the throttling probably should not be there for non-Windows at all.
Conclusion
I am pleased that the performance of ConPTY with JNA is close to the new dedicated Microsoft Terminal and much faster than VSCode. Therefore I plan to focus my time on other areas of the terminal, like WSL integration and bug fixes with larger impacts. I am grateful to the community’s contributions and I will happily support/test/integrate any improvements, such as the upcoming Ctrl-Click functionality that was contributed by Fabrizio Iannetti and will be available in Eclipse IDE 2021-06.
Because much of the performance slowdown is because of ConPTY itself, which is actively being developed at Microsoft I hope that Eclipse will benefit from those performance improvements over time. There is no plan to remove the WinPTY implementation anytime soon, so if there is a user who feels impacted by the slowdown I encourage them to reach out to the community (cdt-dev mailing list, tweet me, comment on this bug or create a bug report).
That also means that any commit/patch you have on CDT before the reformat will almost certainly not apply cleanly.
Therefore I have created this guide for you to reformat your commit and make it easier for you to submit your updated patch to gerrit.
To be able to rebase your commit onto the current master you need to create a version of it with the new formatting. At a high-level the steps we are going to do are:
Reformat your commit with CDT’s new coding style
Create a commit against the pre-formatted CDT that has only the files your commit changed formatted – but without your other changes
The diff between 1 and 2 above is an updated version of the diff for your real change.
Step-by-step this breaks down as:
Pre-requisites
Modern bash shell with sed, awk, grep, git, python, etc
In Clean Up preferences uncheck the “Show profile selection dialog for the ‘Source > Clean Up’ Action”
Copy releng/scripts/cleanup.py somewhere outside of your gitroot so you can access it as the branches change later
Set ECLIPSE environment variable to path to eclipse on your machine to make some of the commands below easier to copy/paste
Step 1: Checkout the commit to rebase
First step is to checkout in CDT repo the commit you want to rebase onto current master. For example if you are updating a commit in gerrit, you could press Download in the top right and copy/paste the Checkout command:
Step 2: Reformat commit to new style
Start by creating a new branch to work on:
git checkout -b commit_to_rebase
Then rebase your change onto commit 35996a5c5ca, where all the per-project formatter settings have been applied, but the code has not been formatted yet. If your original commit is not too far behind this will finish without conflicts. If you have any conflicts, resolve them now.
git rebase 35996a5c5ca5c254959ba48241eaada6dbf8628d
Reformat the code to current standard using the following steps:
Step 2a: Close open editors in Eclipse
The EASE script will run on all open editors, so make sure to start with no open editors.
Step 2b: Open all the Java files modified in your commit
Using git’s diff-tree command we can get all the Java files as a list and then open them with Eclipse.
Create a new Run Launch Configuration of type EASE Script
In Script Source browse the filesystem to where you saved cleanup.py earlier
Ensure Execution Engine is set to Python (Py4J)
Press Run
Each open editor will have the clean up actions run, and then be closed.
Step 2d: Remove trailing whitespace in files
CDT’s code standards require trailing whitespace to be removed from all files marked with remove trailing whitespace in .gitattributes. To do this, run this bit of shell:
git show master:.gitattributes | awk '/# remove trailing whitespace/{getline; print $1}' |
while read i ; do
echo "Removing trailing whitespace on $i files"
git diff-tree --no-commit-id --name-only -r commit_to_rebase -- "$i" | xargs --no-run-if-empty sed -i 's/[ \t]*$//'
done
Step 2e: Save/commit cleanup changes
Update the change to now contain the formatted files.
In this step create a commit that has only the files modified in the original commit cleaned up, but no other ones. This will be the base for the diff we create later.
Step 3a: Create a new branch
Start by checking out to a new branch the same commit as above with the formatter settings
Repeat Step 2a to Step 2d above to cleanup the files.
Step 3c: Save/commit cleanup changes
Save the files which are now formatted, but without the change you wish to rebase in a commit
git add -u
git commit -m"formatted files"
Step 4: Create a new commit that can be cherry-picked to master
Apply the change so you have a history on commit_to_format branch that is two ahead of 35996a5c5c, the first being the formatted files created in step 3, the second being the change we are trying to get onto master, which will be created now
Step 4a: Diff and apply the change
Diff the two branches we just made, that diff is the real work you are trying to get on master, and apply that diff
You now have a commit, marked with commit_to_format, that can be cherry-picked onto master. If other commits have made a conflicting edit since the reformat you may have some conflicts to resolve when you do this cherry-pick
And that is it. Hopefully you have now recreated your patch with just a few automated steps, instead of a painful manual copy+paste job. These instructions are also in the CDT repo in releng/scripts/rebase_helper.sh.
This set of steps shows that there are still some more automatable things that could be done. In particular being able to run Code Clean Ups from the command line in Eclipse would be really nice. Eclipse’s Java code formatter can be run from the command line.
I always want more time in my day. And that’s because I waste all my time trying to think of new ways that would save me time. Which brings me to Github pull requests. One thing I often wish for when reviewing a Github PR: why can’t I quickly jump to the definition of a method being used? Or see where else that piece of code is being called from? Some quick code navigation features would help me do reviews better and quicker. I’ve been spoilt on code completion features in Eclipse IDE and now I want them everywhere. Luckily I get to be in a position I can aim to make that happen.
In thinking about how we can make developer tools and features ubiquitous, I came up with my latest talk: the future of IDEs. I first did this talk within the Internet of Things domain at Thingmonk and had some great feedback. James Governor of Redmonk had this to say about it:
Tracy Miranda, founder of Kichwa Coders, gave us a whistlestop tour of the future of dev tools for IoT. Miranda is a fixture in the Eclipse community, but did a great job of laying out the tools landscape. And of course Microsoft Visual Studio Code got a favourable mention (so much love out there for Code right now, it’s the modern goldilocks text editor). That said, for programming digital twins, she argued we’re going to need visual tools and models, beyond a text editor. Node-Red of course also got a mention.
This talk covers everything from the massive fragmentation with languages and frameworks to making our developer tools more visual, smarter and really so they work everywhere. Even in Github PRs. If you work in developing tools or have strong opinions about how developer tools should work, then this talk is a must watch.
After Thingmonk and the great feedback, I got to refine the talk and present it at Jax London as the ‘Future of IDEs‘. That talk wasn’t recorded but we did manage to have a quick chat about it afterwards, check out the short version (+ extras) here:
A Debug Menu!
The next major release of Eclipse (4.8 aka Photon) due in June 2018 has a small – but significant – new feature. The next version will have a Debug menu!
This improves things in two ways:
No more going to awkwardly names Run menu when you want to Debug
A less full Run menu as the sometimes overlong Run menu is now split into two distinct and logical parts.
Better Default Layout in Debug Perspective
The first thing I do whenever I create a new workspace is change to the Debug Perspective and do most of my work in that perspective, rarely changing to other perspectives. I re-position the views in the perspective in my own special way, or so I thought until I found out that lots of other developers also prefer roughly the same layout as I have. The new default layout gives more place to the editor and more vertical space to the Debug view (the one with the stack traces).
Here is what the new layout looks like with a few additional views open:
So what?
“So what?” I hear you say, “these are small changes, not earth shattering new features.” Changes like this are a big deal, thanks to the marginal gains principle. Eclipse has been a very stable top class IDE for years, but you may have noticed that things haven’t been changing as much in the last number of years. Part of this is down to it being a great IDE already, but other stuff is at play here. Making fundamental changes like the default layout to probably the most commonly used perspective and changing the top level debug menu is a sign that the Eclipse community is alive and well, that the ideas are still coming in. But it also means that the leaders in the community are open to change and evolution. If we don’t evolve we die.
What this means for extenders and plug-in writers?
If you, like me, are developing and extending Eclipse there is some impact on you to. For example, if you are contributing a clearly debug related task to the Run menu, you probably want to start contributing it to the Debug menu going forward. Both so your users can find it and so it does not stand out as being in the wrong place. You probably also want to consider the default opening location for any additional views you provide to the Debug perspective to ensure they pop-up in the logical place.
Of course it goes further than this. You should also take a step back and consider how your tools work. Perhaps it is time to do a Lean Design Critique?
Finally thank you to the Eclipse Platform committers and contributors who are taking the bold steps to change and evolve. A particular thanks to Andrey Loskutov, from whom I borrowed the screenshots from (via Bug 464898 and Bug 513355), see Andrey announcement on the Eclipse mailing list: https://dev.eclipse.org/mhonarc/lists/cross-project-issues-dev/msg14986.html