
Xtext is the popular Eclipse language development framework for domain specific languages. Its sweet spot is JVM-languages and it is excellent for languages where you can define the grammar yourself. But how well can Xtext cope with a non-JVM language that has undergone decades of evolution?
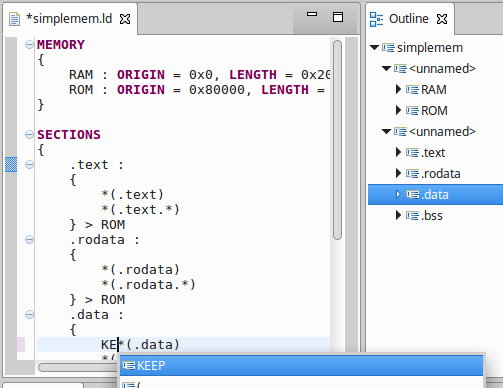
In our case, we want to see if we can take advantage of Xtext to create an editor for C/C++ linker scripts in CDT. Linker scripts are used to specify the memory sections, layouts and how code relates to these sections. Linker scripts consist of the ld command language, and this is what a simple typical script might look like:
MEMORY {
RAM : ORIGIN = 0x0, LENGTH = 0x2000
ROM : ORIGIN = 0x80000, LENGTH = 0x10000
}
SECTIONS {
.text : { *(.text) *(.text.*) } > ROM
.rodata : { *(.rodata) *(.rodata.*) } > ROM
.data : { *(.data) *(.data.*) } > RAM
.bss : { _bss = .; *(.bss) *(.bss.*) *(COMMON) _ebss = .; _end = .; } > RAM
}
Alternatives to Xtext
Besides using Xtext, its worth considering some of the other options there are for this task:
- Roll-your-own – the existing C/C++ Editor in CDT does this, gives full control, best error-recovery and supports bidirectionality, recreating source from abstract syntax tree (AST), but it is a last resort as it would be an incredible amount of work that would take a long time to get right.
- Antlr – write your own antlr grammar, but since antlr is already used in Xtext, may as well use Xtext and get benefits of Eclipse editor integration
- Reuse linker’s bison grammar – would give perfect parsing, but it is a no-go because i) it’s GPL ii) it generates C code not Java & iii) requirements for editing are much more strenuous than for linking and this for example, would not support bidirectionality (i.e you can’t recreate the linker file from the AST).
Benefits of Xtext
The Xtext framework additionally provides these nice features we are interested in:
- Parsing, lexing & AST generation
- serialisation support is particularly important to support bidirectionality and preserve users comments, whitespace etc.
- Rich Editor Features
- syntax highlighting
- content assist
- validation & error markers
- code folding & bracket matching
- Integrated Outline editor
- Ecore model generation which can be used for integration with UI frameworks such as EMF Forms, Sirius, etc.
Linker Script Parsing Challenges
When we talk about the ld command language being a non-JVM language, here are some specific challenges related to what that means.
- Crazy Identifiers! The following are valid identifiers in linker scripts:
- .text
- *
- hello*.o
- “spaces are ok, just quote the identifier”
- this+is-another*crazy[example]
- Identifier or Number? Things that appear to be identifiers may actually be numbers:
- a123 – identifier
- a123x – number
- 123y – identifier
- 123h -number
- Identifier or Expression?
In the grammar 2+3, for example, depending on context, can either be an identifier or an expression:
SECTIONS {
.out_name : {
file*.o(.text.*)
2+3(*)
symbol = 2+3;
}
}
The first 2+3 is a filename, so almost anything that can be a filename is allowed there. The second 2+3 is an expression to be assigned to symbol.
Resolutions
Here’s what we did to support the linker language as far as we could:
- Custom Xtext grammar – as extending the XType grammar does not make sense, the main job is to craft the grammar to understand all the linker script identifier and expressions specifics. This involves iterating as we add in more and more language feature support, here’s the work in progress.
- Limited Identifier Support – in some cases we opted to not support certain identifiers unless they are escaped (double-quoted). While linker scripts theoretically support such identifiers (e.g. 1234abcd) we have not found a single case yet of an identifier that would actually need escaping. If one did crop up, the user could adjust it to work with the editor (e.g. “1234abcd”).
- Context Based Lexing – knowing the difference between an identifier or expression would require context based lexing rules. However this will not work with the antlr lexer. We have the option to replace it with a custom or external lexer. This is an option that can be considered in the future if desirable.
Conclusion
Xtext is a great language development framework. While Xtext may not be able to support every theoretical case of the long-lived linker script command language, it can be used to provide a very high level of support for the common features. Support for context based lexing in the future would enable a higher level of language support. Xtext can be used to provide a rich language editor with syntax colouring, command completion, integrated outline view & more in a relatively short space of time. A powerful linker script editor is another great feature for C/C++ developers that use CDT, the reference C/C++ IDE in the industry.

Sounds interesting. A few comments/hins:
– Have you considered switching to a JFlex-based lexer? We do that in a number of our Xtext projects as it is more powerful. See http://typefox.io/taming-the-lexer for details.
– This language seems to be hard to implement with the tight coupling of AST-model and syntax that Xtext provides OOTB. If it gets too tough, you could consider parsing into a more relaxed AST and than transform that into the model you want to go on processing. Dig for an interface called IDervivedStateComputer.
– If you need to get access to the text that was parsed to produce a certain model element, e.g. when an expression eventually turns out to be an identifier, you can use the NodeModelUtils.
Hi Jan, Thanks for the really useful insights and the link. It sounds like we are on the right starting point with place to grow. My next focus is on making sure our model is fit for purpose, as well as adding the still to support features of the linker script. It is good to have confirmation that if things get too tough we can switch out just part of the implementation, but all the rest of the code based on the model will be unchanged. –Jonah
@Jan Köhnlein, I did not understand your second point. Did you mean to say, that I could perhaps define tokens using the least overlapping grammar, and in some kind of post-processing change my tokens based on context. Like perhaps remove all problematic characters from allowed identifiers so that lexer grammar is simplified. Then somehow decide later if more than one tokens make up one identifier? How can one do that?
Yes, that was what came to my mind. Parse/lex it loosely into some intermediate model, and then transform this using the IDerivedStateComputer into a completely different, semantically exact model, taking all the context sensitive rules into account. Then use the latter in all further processing steps.
This might be pretty hacky and add a lot of additional parser/lexer logic in the transformation step.
Thanks for an interesting read. I remembered doing something like that quite a while back. I think at least ANTLR 2 can be convinced to do what you want. In ANTLR parlance it is called lexer multiplexing and can be used to treat the same token as two different types depending on the context. In a very old project of mine I used this technique to parse different sections of a program, similar to linker scripts.
I looked into a similar thing when doing a Xtext based parser for a system test scripting language and discovered that Xtext limited me to having only one lexer. So I discussed this with some of the Xtext team and learned that it should be possible to do something to the same effect. However, I never got the chance to follow up on that.
Thanks Torkild. Good to know what others have tried before & possible options. Hadn’t come across the term lexer multiplexing so may be useful in future searches.
I have an almost exactly the same problem as the post describes above. In my case I am wrestling with the Device Tree Syntax (http://devicetree.org).
It has pretty weird identifiers too, having characters such as these: a-zA-Z0-9,._+*#?@-. So basically we cannot identify without context whether a text such as “a-b” is an expression, or an identifier. In fact, we cannot even know if a sequence such as “11” is an integer or an identifier.
Consequently, Xtext’s context-less lexer cannot handle this grammar. In my effort to find a solution I am at the point of exploring a custom lexer. However, I am pretty much a novice with Xtext, so wish me luck!
Sounds interesting, good luck!