

While looking to the future of debugger tooling, it is still important to consider the prior art and the solutions that have stood the test of time. For embedded development, gdb is high on that list, so it is worth considering if gdb’s interface could be the basis of a debug protocol.
If you’ve used gdb to debug C/C++ code then you are probably aware of MI, the machine interface layer used to communicate between the debugger backend and the IDE front end. MI is not only used by gdb but also adopted by lldb (the defacto debugger for Swift) and more recently by clrdbg (.NET Core). MI defines a rich set of functionality from standard debug run control and breakpoints up to advanced features for multi-process debug, reverse debugging and dynamic printf. With MI being pretty pervasive and supporting such rich functionality, it is tempting to think it might make the basis of a good debug protocol. However in practice it lacks some of the qualities of a good protocol:
1. A Specification
We once had the opportunity to work on a project where the brief was to integrate into Eclipse IDE/CDT a custom debugger that ‘implemented the MI spec’. We can tell you we learnt the hard way that MI has plenty of useful documentation but no spec to speak of. This matters when you get into the nitty gritty of implementation details for example: what syntax should be used to notify when a bad condition has been created on a breakpoint?
The documentation does not necessarily reflect what the code does, some command or command variants have inconsistencies with the source code or don’t reflect platform dependent issues. For example, the -exec-step-instruction in practice takes an argument (e.g -exec-step-instruction 1) even though this is not documented.
The main message here is documentation, even good documentation as in the case of gdb, is not the same as a protocol specification, so one can’t blindly implement to the docs (and if you think it’s just a case of looking at the code… well, which version?- see #4 below).
2. Clean Interfaces with no Idiosyncrasies
This piece of code from Visual Studio’s MIEngine demonstrates how rife MI is with idiosyncrasies. The code launches a debugger which will use MI to communicate i.e. to gdb, lldb or clrdbg. There are special cases for each tool that an IDE just shouldn’t need to know about:
- Different ways of specifying a working directory depending on the tool
- Environment variables are set differently: before launch for gdb/lldb after for clrdbg
- Details of which Operating System the debugger is being run on
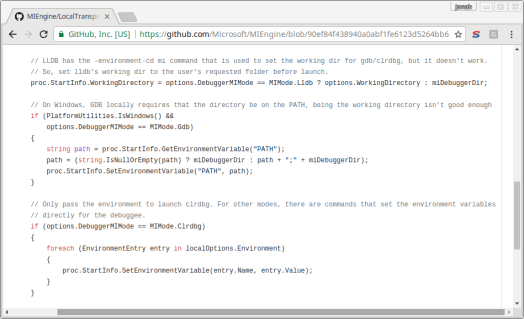
And this is even before you launch MI. In Eclipse CDT just after launching MI, the IDE has to know about and issue commands about all sorts of things e.g. ‘set print sevenbit-strings on’ c’mon, really, seriously? Tom sums it up nicely:
“It is an oddity that currently an MI consumer must check gdb’s host charset in order to know how to decode its output.“
Once you get into actual debugging there’s a fair amount of ‘need-to-know’ for special cases & exceptions. A protocol needs to steer-clear of implementation details, but in the case of MI these have all too often leaked in.
3. Fit for Purpose
As MI was not specifically designed to be a protocol, not suprisingly there are a few behaviour specific things that make it not fit to be a protocol. For example:
- If your program prints to stdout, then that can corrupt the output stream of MI, breaking the instructions.
- In some cases GDB responds twice from a single command. In such cases, for example Eclipse CDT has a special MIAsyncErrorProcessor class just to manage such cases.
4. Versioning
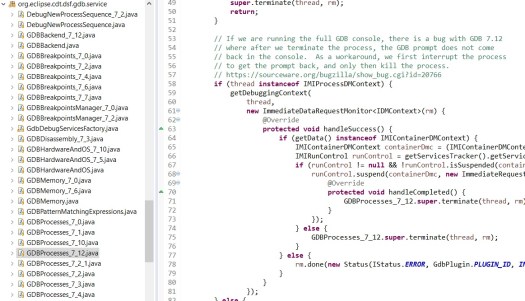
A good protocol has defined versions that clients and subscribers can adapt to. With each new version of GDB, MI has subtle differences that make client implementation long-winded and difficult to maintain. For example, in Eclipse CDT’s gdb debugger implementation (DSF) separate classes are created to manage differences in MI in different versions of gdb. There are 5 different breakpoint classes, 7 different run control classes, etc And this is just gdb versions, let alone lldb or clrdb – imagine trying to implement wide-scale support for all those in a new IDE!
Conclusion
While feature-rich and ubiquitous, gdb’s MI is a reasonable syntax, but not a good debug protocol. A good protocol needs much more than that – clean interfaces, fit for purpose, a spec & versioning – if it is really going to make common debugger implementations easier.

Tracy,
You make some good points – in particular documentation can be both better and more general, not tied to GDB. There was effort to turn MI into a generic spec once, I recall, but it died before making any progress. The things you point in item 2 are mostly due to different tools implementing things differently, for lack of clear spec telling them what to do, so again related to documentation. I don’t quite agree about your items 3 and 4.
– If you run GDB using pipes and allow the inferior to use the same stdout, there’s nothing MI can do. That’s why on Linux, allocating pseudo-terminal for program output is pretty much the only sane way.
– Double responses from commands are not defect in the protocol – in fact, the comment in MIAsyncErrorProcessor explains how it can happen. In general, if you have async, non-stop, breakpoints, tracepoints and conditions, then you can get error in the middle of execution, and UI has to handle it, no matter what.
– MI has versioning with the ‘list-features’ command. The fact that Eclipse has zillion command factories and 7 run control classes is mostly the result of wanting to keep compatibility with some rather old GDB versions. Maybe a better solution for that is supporting only the most recent GDB. Commercial vendors that want to support old GDB can be reasonably expected to put the effort for that.
It is possible that a ground-up redesign will be better, but in my opinion most of the complexity is part of the domain, and a redesign can easily regress the most complex parts.
Very good point ! The Standard debug protocol should express communication between abstract debugger UI and abstract debugger server. UI and server are decoupled and could be implemented independently by independent teams,